
728x90
< 라이브러리(Library) >
- Library는 여러 패키지와 모듈들을 모아놓은 것을 의미한다.
< 패키지(Package) >
- package는 특정 기능과 관련된 여러 모듈을 한 폴더 안에 넣어 관리하는데 이를 패키지라고 한다.
- 예를 들어 Test라는 폴더 안에 init.py, test.py와 같은 파일들이 모여있는 것이다.
< 모듈(module) >
- Module은 함수, 변수, 클래스를 모아놓은 것을 말함
- 일반적으로 한 파일을 말하는데 예를 들어 .py와 같은 하나의 파일 안에 함수와 변수, 클래스가 모여있는 것으로 볼 수 있음
라이브러리 >= 패키지 >= 모듈
< Pandas >
- 구조화된 데이터의 처리를 지원하는 Python 라이브러리
- Python계의 엑셀!
- 고성능 Array 계산 라이브러리인 Numpy와 통합하여, 강력한 “스프레드시트” 처리 기능을 제공
- Numpy에서 사용할 수 있는 고성능 기능들을 그대로 재현 : numpy를 내포하고 있음
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공함
In [288]:
import pandas as pd
In [289]:
data_url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
# data_url = './housing.data'
df_data = pd.read_csv(data_url, sep = '\s+', header = None )
# csv 데이터 타입 로드, separate는 빈공간으로 지정하고, Column은 없음
In [290]:
df_data.head() # 처음 5줄 출력
Out[290]:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
In [291]:
df_data.columns = [
'CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDV'
]
# Column Header 이름을 지정
df_data.head()
Out[291]:
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | MEDV | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296.0 | 15.3 | 396.90 | 4.98 | 24.0 |
| 1 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242.0 | 17.8 | 396.90 | 9.14 | 21.6 |
| 2 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242.0 | 17.8 | 392.83 | 4.03 | 34.7 |
| 3 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222.0 | 18.7 | 394.63 | 2.94 | 33.4 |
| 4 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222.0 | 18.7 | 396.90 | 5.33 | 36.2 |
In [292]:
type(df_data.values)
# numpy 데이터 타입Out[292]:
numpy.ndarray1. DataFrame Overview
< Pandas의 구성 > : Index + (column) -> Value
- Series : DataFrame 중 하나의 Column에 해당하는 데이터의 모음 Object -> index를 내가 임의로 설정가능 / data index에 접근 및 수정은 dictionary처럼 가능 -> Column vector를 표현하는 object
- index(Column Vector) -> value(Column Vector) 형태로 구성
- subclass of numpy.ndarray
- Data : any type
- Index labels need not be ordered
- Duplicates are possible


- DataFrame : Data Table 전체를 포함하는 Obejct (Matrix)
- index(Column vector) & columns(Row vector) = 세로축 & 가로축 -> value(Matrix) 형태로 구성
- NumPy array-like
- Each column can have a different type
- Row & Column index
- Size mutable: insert & delete columns
- DataFrame()안에 data를 입력
- Dictionary : index나 columns를 key와 동일하게 맞춰서 가로, 세로 배열 모두 가능
- {column_name : data(list), column_name2 : data2(list), ... }
- 주로 columns = [ key로 구성된 list 가져옴 ]
- 각 세로축의 data들을 dict의 value로 채움
- 2 dimension-list : 무조건 가로 배열만 가능함
- Dictionary : index나 columns를 key와 동일하게 맞춰서 가로, 세로 배열 모두 가능







In [293]:
list_data = [1,2,3,4,5]
list_name = ["a", "b", "c", "d", "e"]
example_obj = pd.Series(data = list_data, index = list_name, dtype = float)
example_obj
Out[293]:
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
dtype: float64In [294]:
example_obj["b"]
# data index에 접근하기
Out[294]:
2.0In [295]:
example_obj["a"] = 3.2
example_obj
# data index에 값 할당하기
Out[295]:
a 3.2
b 2.0
c 3.0
d 4.0
e 5.0
dtype: float64In [296]:
example_obj.values
Out[296]:
array([3.2, 2. , 3. , 4. , 5. ])In [297]:
example_obj.index
Out[297]:
Index(['a', 'b', 'c', 'd', 'e'], dtype='object')In [298]:
# Series.name : Data의 이름을 지정
# Series.index.name : Index의 이름을 지정
example_obj.name = 'number'
example_obj.index.name = 'alphabet'
example_obj
Out[298]:
alphabet
a 3.2
b 2.0
c 3.0
d 4.0
e 5.0
Name: number, dtype: float64In [299]:
# Series data에 dictionary 형태도 가능 (세로로 배열하고 싶을 경우)
dict_data = {
'a':1, 'b':2, 'c':3, 'd':4, 'e':5
}
indexes = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
series_obj = pd.Series(data = dict_data , index=indexes)
series_obj
Out[299]:
a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
f NaN
g NaN
h NaN
dtype: float64




In [300]:
# Example from - https://chrisalbon.com/python/pandas_map_values_to_values.html
raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
'age': [42, 52, 36, 24, 73],
'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city', 'random'])
df
Out[300]:
| first_name | last_name | age | city | random | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | NaN |
| 1 | Molly | Jacobson | 52 | Baltimore | NaN |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
In [301]:
raw_data2 = [
['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
[42, 52, 36, 24, 73],
['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']
]
df2 = pd.DataFrame([list(x) for x in zip(*raw_data2)], columns = ['first_name', 'last_name', 'age', 'city'])
df2
Out[301]:
| first_name | last_name | age | city | |
|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco |
| 1 | Molly | Jacobson | 52 | Baltimore |
| 2 | Tina | Ali | 36 | Miami |
| 3 | Jake | Milner | 24 | Douglas |
| 4 | Amy | Cooze | 73 | Boston |
In [302]:
pd.DataFrame(raw_data, columns = ["age", "city"])
Out[302]:
| age | city | |
|---|---|---|
| 0 | 42 | San Francisco |
| 1 | 52 | Baltimore |
| 2 | 36 | Miami |
| 3 | 24 | Douglas |
| 4 | 73 | Boston |
In [303]:
new_df = pd.DataFrame(raw_data,
columns = ["first_name","last_name","age", "city", "debt"]
)
# Series 추출하기 (df.method, df[column])
print(new_df.first_name)
print()
print(new_df['first_name'])
0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
- Slicing
- df.loc[index_name] : 끝자리가 인덱스의 '이름'이므로 끝 인덱스 포함
- df.iloc[index_number] : 끝자리가 인덱스의 '숫자'이므로 끝 인덱스 포함X


df
Out[304]:
| first_name | last_name | age | city | random | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | NaN |
| 1 | Molly | Jacobson | 52 | Baltimore | NaN |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
In [305]:
df.city
Out[305]:
0 San Francisco
1 Baltimore
2 Miami
3 Douglas
4 Boston
Name: city, dtype: objectIn [306]:
df.iloc[3]
Out[306]:
first_name Jake
last_name Milner
age 24
city Douglas
random NaN
Name: 3, dtype: objectIn [307]:
df.age.iloc[3]
Out[307]:
24In [308]:
df
Out[308]:
| first_name | last_name | age | city | random | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | NaN |
| 1 | Molly | Jacobson | 52 | Baltimore | NaN |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
In [309]:
import numpy as np
In [310]:
# Example from - https://stackoverflow.com/questions/31593201/pandas-iloc-vs-ix-vs-loc-explanation
s = pd.Series(np.nan, index=[49,48,47,46,45, 1, 2, 3, 4, 5])
s
Out[310]:
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
dtype: float64In [311]:
s.loc[46:]
Out[311]:
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
dtype: float64In [312]:
s.iloc[3:]
Out[312]:
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
dtype: float64다른 Property로부터 새로운 feature를 만들어줄 때 유용하게 사용
- 새로운 column을 먼저 blank로 만들기
- 새로운 column에 기존 column의 조건문으로 데이터 할당하기




In [313]:
# 먼저 새로운 column을 만들어주긴 해야함 (NaN)
new_df.debt = new_df.age > 40
new_df
Out[313]:
| first_name | last_name | age | city | debt | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | True |
| 1 | Molly | Jacobson | 52 | Baltimore | True |
| 2 | Tina | Ali | 36 | Miami | False |
| 3 | Jake | Milner | 24 | Douglas | False |
| 4 | Amy | Cooze | 73 | Boston | True |
In [314]:
new_df.T
Out[314]:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| first_name | Jason | Molly | Tina | Jake | Amy |
| last_name | Miller | Jacobson | Ali | Milner | Cooze |
| age | 42 | 52 | 36 | 24 | 73 |
| city | San Francisco | Baltimore | Miami | Douglas | Boston |
| debt | True | True | False | False | True |
In [315]:
# Column을 삭제함
del new_df['debt']
new_df
Out[315]:
| first_name | last_name | age | city | |
|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco |
| 1 | Molly | Jacobson | 52 | Baltimore |
| 2 | Tina | Ali | 36 | Miami |
| 3 | Jake | Milner | 24 | Douglas |
| 4 | Amy | Cooze | 73 | Boston |
2. Selection & Drop
- Selection with column names : df['string'] -> Column
- Selection with index number : df[number(int)] -> Row


In [316]:
df
Out[316]:
| first_name | last_name | age | city | random | |
|---|---|---|---|---|---|
| 0 | Jason | Miller | 42 | San Francisco | NaN |
| 1 | Molly | Jacobson | 52 | Baltimore | NaN |
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
In [317]:
df[2:]
Out[317]:
| first_name | last_name | age | city | random | |
|---|---|---|---|---|---|
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
In [318]:
df.iloc[2:]
Out[318]:
| first_name | last_name | age | city | random | |
|---|---|---|---|---|---|
| 2 | Tina | Ali | 36 | Miami | NaN |
| 3 | Jake | Milner | 24 | Douglas | NaN |
| 4 | Amy | Cooze | 73 | Boston | NaN |
In [319]:
df['last_name'].head(3) # 한 개의 column 선택시
Out[319]:
0 Miller
1 Jacobson
2 Ali
Name: last_name, dtype: objectIn [320]:
df[['last_name', 'age', 'first_name']].head(2) # 한 개 이상의 column 선택시
Out[320]:
| last_name | age | first_name | |
|---|---|---|---|
| 0 | Miller | 42 | Jason |
| 1 | Jacobson | 52 | Molly |
DataFrame의 데이터 접근법 : 추가 / 삭제 / 선택
1. 선택
- Series 가져오기 (<- DataFrame)
- df.column_name
- df['column_name'(string)]
- Series 가져오기 (<-Series)
- df.loc[index_name] : index location (index 이름) = '이름'기준
- df.iloc[index_numer] : index position (index 숫자) = '순서'기준
- df[index] : value 가져옴
- index 가져오기 (location) (<- DataFrame)
- df.loc[index_name] : index location (index 이름) = '이름'기준
- df.iloc[index_number] : index position (index 숫자) = '순서'기준
- df[number(int)] : df.iloc[] 과 기능이 동일함
- Basic, loc, iloc Selection
- Column & index number : df[["name","street"]][:2]
- Column & index name : df.loc[[211829,320563],['name','street']]
- Column number & index number : df.iloc[:2,:2]
- Boolean index w/ condition
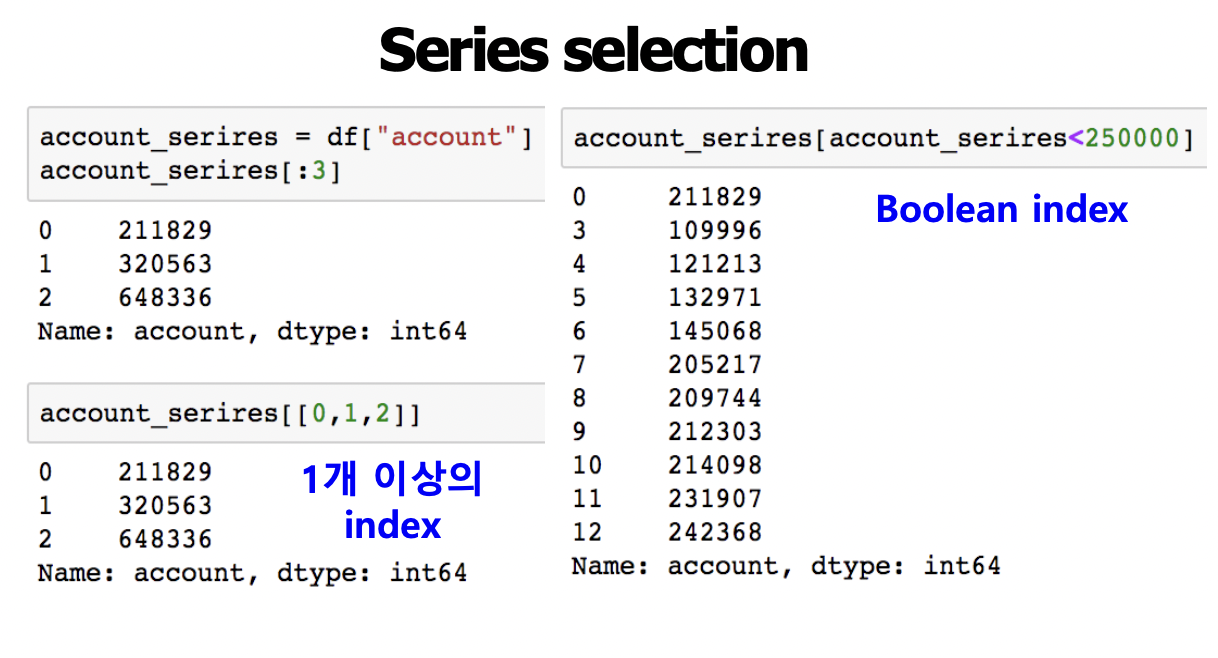
- 1개 이상의 index처리 : [[1,5,2]] or [['city', 'age']] 와 같이 처리가능
- Boolean index : age_series[age_series>40]
< boolean index >
- array의 [index]에 condition(boolean 조건)을 넣는 경우 filter로서 작용함
- True인 index가 아니라 value를 반환함
- numpy는 배열은 특정 조건에 따른 값을 배열 형태로 추출할 수 있음
- Comparison operation 함수들도 모두 사용가능
- condition에 해당하는 원소만 뽑을 때 : 조건이 True인 index의 element만 추출
- Where : 특정 condition에 해당하는 index를 반환
- Boolean index : 특정 condition에 해당하는 value를 반환
< fancy index > : a[b], a.take(b)
- numpy는 array(b)를 index value로 사용해서 값을 추출하는 방법
- Matrix 형태의 데이터도 가능
- 단, b는 반드시 모든 원소가 int여야 함 : 정수로 선언 -> a[b] : b를 index로 인식해서 b의 각 원소(인덱스)마다 a의 값을 반환 -> a.take(b) : bracket index와 같은 효과
- a[b,c] : b를 row index, c를 column index로 변환하여 처리 가능
2. 추가 / 삭제
- Column 변경하기
- 추가:
- df['new_column'] = df['기존_column'].apply(function)
- df['new_column'] = condition 조건문
- column_list에 추가할 column의 이름을 넣어서 pd.Dataframe으로 재정의
- 삭제:
- del df["column_name"]
- df.drop('column_name', axis=1)
- 추가:
- Index 변경하기
- 수정: df.index = 수정할 리스트 or df["column_name"]와 같이 column을 index에 넣기 등
- 삭제:
- del df['series_example]
- Index name으로 drop : df.drop(1)
- 한 개 이상의 Index name으로 drop : df.drop([0,1,2,3])
- axis 지정으로 축을 기준으로 drop -> column 중에 'city' : df.drop("city", axis=1)
- index 재설정
- df.index = list(range(0,15))
- df.head()
In [321]:
cities = df['city']
cities[2:]
Out[321]:
2 Miami
3 Douglas
4 Boston
Name: city, dtype: objectIn [322]:
cities[[2,3,4]]
Out[322]:
2 Miami
3 Douglas
4 Boston
Name: city, dtype: objectIn [323]:
age_series = df.age
age_series[age_series>40]
Out[323]:
0 42
1 52
4 73
Name: age, dtype: int64
In [324]:
df.index = df['age']
del df['age']
df
Out[324]:
| first_name | last_name | city | random | |
|---|---|---|---|---|
| age | ||||
| 42 | Jason | Miller | San Francisco | NaN |
| 52 | Molly | Jacobson | Baltimore | NaN |
| 36 | Tina | Ali | Miami | NaN |
| 24 | Jake | Milner | Douglas | NaN |
| 73 | Amy | Cooze | Boston | NaN |

In [325]:
df[["first_name","last_name"]][:2]
Out[325]:
| first_name | last_name | |
|---|---|---|
| age | ||
| 42 | Jason | Miller |
| 52 | Molly | Jacobson |
In [326]:
df.loc[[42,52,36],['first_name','city']]
Out[326]:
| first_name | city | |
|---|---|---|
| age | ||
| 42 | Jason | San Francisco |
| 52 | Molly | Baltimore |
| 36 | Tina | Miami |
In [327]:
df.iloc[:2,:3]
Out[327]:
| first_name | last_name | city | |
|---|---|---|---|
| age | |||
| 42 | Jason | Miller | San Francisco |
| 52 | Molly | Jacobson | Baltimore |

In [328]:
df.index = list(range(0,5))
df
Out[328]:
| first_name | last_name | city | random | |
|---|---|---|---|---|
| 0 | Jason | Miller | San Francisco | NaN |
| 1 | Molly | Jacobson | Baltimore | NaN |
| 2 | Tina | Ali | Miami | NaN |
| 3 | Jake | Milner | Douglas | NaN |
| 4 | Amy | Cooze | Boston | NaN |
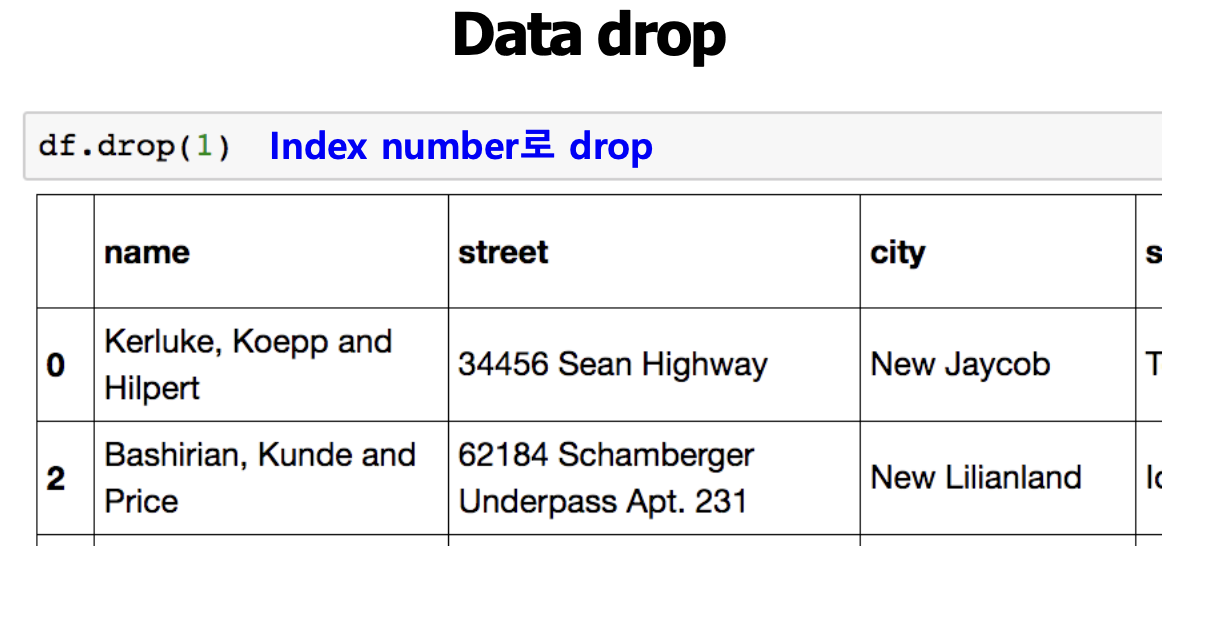
< Data Drop > :
- 원본 데이터(df)는 남아있음(수정되지 않음)
- 즉, drop 이후에도 원본 df는 변경되지 않은 상태로 남아있음
- 원본까지 변경하고 싶다면 inplace=True 라는 parameter를 따로 추가해줘야 함
- df.drop("city", axis=1, inplace=True)
- Column을 제거할 때
- del df['series_example]
- df.drop('column_name', axis=1)
- Row를 제거할 때
- Index name으로 drop : df.drop(1)
- 한 개 이상의 Index name으로 drop : df.drop([0,1,2,3])
- axis 지정으로 축을 기준으로 drop -> column 중에 'city' : df.drop("city", axis=1)


In [329]:
df
Out[329]:
| first_name | last_name | city | random | |
|---|---|---|---|---|
| 0 | Jason | Miller | San Francisco | NaN |
| 1 | Molly | Jacobson | Baltimore | NaN |
| 2 | Tina | Ali | Miami | NaN |
| 3 | Jake | Milner | Douglas | NaN |
| 4 | Amy | Cooze | Boston | NaN |
In [330]:
df.drop('random', axis=1)
Out[330]:
| first_name | last_name | city | |
|---|---|---|---|
| 0 | Jason | Miller | San Francisco |
| 1 | Molly | Jacobson | Baltimore |
| 2 | Tina | Ali | Miami |
| 3 | Jake | Milner | Douglas |
| 4 | Amy | Cooze | Boston |
In [331]:
df
Out[331]:
| first_name | last_name | city | random | |
|---|---|---|---|---|
| 0 | Jason | Miller | San Francisco | NaN |
| 1 | Molly | Jacobson | Baltimore | NaN |
| 2 | Tina | Ali | Miami | NaN |
| 3 | Jake | Milner | Douglas | NaN |
| 4 | Amy | Cooze | Boston | NaN |
In [332]:
df.drop("random", axis=1, inplace=True)
In [333]:
df
Out[333]:
| first_name | last_name | city | |
|---|---|---|---|
| 0 | Jason | Miller | San Francisco |
| 1 | Molly | Jacobson | Baltimore |
| 2 | Tina | Ali | Miami |
| 3 | Jake | Milner | Douglas |
| 4 | Amy | Cooze | Boston |
3. Dataframe Operations
< Series operation >
- index(이름)를 기준으로 연산 수행
- 겹치는 index가 없을 경우 NaN 값으로 반환
- 겹치는 index가 있을 경우 value끼리 연산수행


< DataFrame operation >
- df는 columns와 index를 모두 고려
- fill_value parameter를 쓰면 NaN값들을 모두 0으로 반환(NaN -> 0으로 처리해서 계산가능)
- df1.add(ddf2, fill_value = 0)
- operation types : add, subs, div, mul
In [334]:
s1 = pd.Series(range(1,6), index=list('abced'))
s1
s1 = pd.Series(range(1,6), index=list('abced'))
s1
Out[334]:
a 1
b 2
c 3
e 4
d 5
dtype: int64In [335]:
s2 = pd.Series(range(5,11), index=list('bcedef'))
s2
Out[335]:
b 5
c 6
e 7
d 8
e 9
f 10
dtype: int64In [336]:
s1.add(s2)
Out[336]:
a NaN
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f NaN
dtype: float64In [337]:
s1+s2
Out[337]:
a NaN
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f NaN
dtype: float64

In [338]:
df1 = pd.DataFrame(
np.arange(9).reshape(3,3),
columns = list('abc')
)
df1
Out[338]:
| a | b | c | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
| 2 | 6 | 7 | 8 |
In [339]:
df2 = pd.DataFrame(
np.arange(16).reshape(4,4),
columns = list('abcd')
)
df2
Out[339]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [340]:
df1 + df2
Out[340]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 | NaN |
| 1 | 7.0 | 9.0 | 11.0 | NaN |
| 2 | 14.0 | 16.0 | 18.0 | NaN |
| 3 | NaN | NaN | NaN | NaN |
In [341]:
df1.add(df2, fill_value=0)
Out[341]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 | 3.0 |
| 1 | 7.0 | 9.0 | 11.0 | 7.0 |
| 2 | 14.0 | 16.0 | 18.0 | 11.0 |
| 3 | 12.0 | 13.0 | 14.0 | 15.0 |
In [342]:
df = pd.DataFrame(
np.arange(16).reshape(4,4),
columns=list('abcd')
)
df
Out[342]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [343]:
s = pd.Series(
np.arange(10,14),
index=list('abcd')
)
s
Out[343]:
a 10
b 11
c 12
d 13
dtype: int64In [344]:
df + s
# column을 기준으로 broadcasting이 발생함
Out[344]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 10 | 12 | 14 | 16 |
| 1 | 14 | 16 | 18 | 20 |
| 2 | 18 | 20 | 22 | 24 |
| 3 | 22 | 24 | 26 | 28 |
4. lambda, map, apply
< Lambda 함수 >
- 한 줄로 함수를 표현하는 익명 함수 기법
- Lisp 언어에서 시작된 기법으로 오늘날 현대언어에 많이 사용
lambda argument : expression


< map 함수 > : 데이터를 변환하는데 유용하게 사용
- 함수와 sequence형 데이터를 인자로 받아
- 각 element마다 입력받은 함수를 적용하여 list로 반환
- 일반적으로 함수를 lambda형태로 표현함
map(function, sequence)
- Series.map(dict_type) : dict 타입으로 데이터 교체 & 없는 값은 NaN
- Series1.map(Series2) : Series1이 가지고 있는 같은 위치의 데이터를 S2로 전환


< map for series > : Value 각각에 적용
- Pandas의 series type의 데이터에도 map 함수 사용가능
- function 대신 dict, sequence형 자료등으로 대체 가능




< Replace function >
- Map 함수의 기능중 데이터변환 기능만 담당
- 데이터 변환시 많이 사용하는 함수

< apply for dataframe> : Series 전체에 함수 적용
- map과 달리, series 전체(column)에 해당 함수를 적용
- 입력값이 series 데이터로 입력받아 handling 가능
- DataFrame.apply(function) : 각 column 별로 나오는 결과를 Series 형태로 반환
- 내장 연산함수를 사용할 때도 똑같은 효과를 거둘 수 있음
- mean, std 등 사용가능
- scalar 값 이외에 series값의 반환도 가능함


< applymap for dataframe >
- series 단위가 아닌 element 단위로 함수를 적용함
- series 단위에 apply를 적용시킬 때와 같은 효과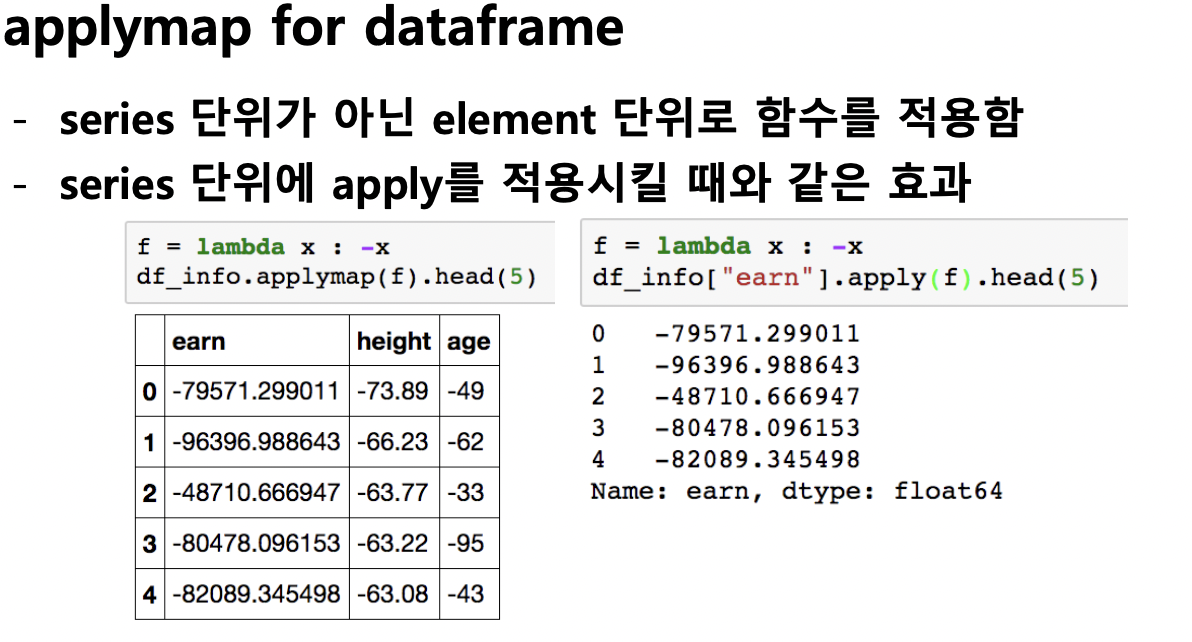
In [345]:
s1 = pd.Series(np.arange(10))
s1.head(5)
s1.map(lambda x : x**2).head(5)
Out[345]:
0 0
1 1
2 4
3 9
4 16
dtype: int64In [346]:
z = {1:'A', 2:'B', 3:'C'}
s1.map(z).head(5)
Out[346]:
0 NaN
1 A
2 B
3 C
4 NaN
dtype: objectIn [347]:
s2 = pd.Series(np.arange(10,20))
s1.map(s2).head(5)
Out[347]:
0 10
1 11
2 12
3 13
4 14
dtype: int64In [348]:
df
Out[348]:
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
| 3 | 12 | 13 | 14 | 15 |
In [349]:
df['test'] = df.a >0
df
Out[349]:
| a | b | c | d | test | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | False |
| 1 | 4 | 5 | 6 | 7 | True |
| 2 | 8 | 9 | 10 | 11 | True |
| 3 | 12 | 13 | 14 | 15 | True |
In [350]:
df.test.replace({'True':1, 'False':0})
Out[350]:
0 False
1 True
2 True
3 True
Name: test, dtype: boolIn [351]:
df.test.replace(['True', 'False'], [1,0], inplace=True)
df
Out[351]:
| a | b | c | d | test | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | False |
| 1 | 4 | 5 | 6 | 7 | True |
| 2 | 8 | 9 | 10 | 11 | True |
| 3 | 12 | 13 | 14 | 15 | True |
In [352]:
df_info = df[['a','b','c']]
df_info.head()
Out[352]:
| a | b | c | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 4 | 5 | 6 |
| 2 | 8 | 9 | 10 |
| 3 | 12 | 13 | 14 |
In [353]:
f = lambda x : x.max() - x.min()
df_info.apply(f)
Out[353]:
a 12
b 12
c 12
dtype: int64In [354]:
f = lambda x: -x
df_info.applymap(f)
Out[354]:
| a | b | c | |
|---|---|---|---|
| 0 | 0 | -1 | -2 |
| 1 | -4 | -5 | -6 |
| 2 | -8 | -9 | -10 |
| 3 | -12 | -13 | -14 |
In [356]:
f = lambda x: -x
df_info['a'].apply(f).head()
Out[356]:
0 0
1 -4
2 -8
3 -12
Name: a, dtype: int64
5. Pandas Built-In Functions
< describe >
- Numeric type 데이터의 요약 정보를 보여줌

< unique >
- series data의 유일한 값을 list를 반환함

< sum >
- 기본적인 column 또는 row 값의 연산을 지원
- sub, mean, min, max, count, median, mad, var 등

< isnull >
- column 또는 row 값의 NaN (null) 값의 index를 반환함
< sort_values>
- column 값을 기준으로 데이터를 sorting
< Correlation & Covariance >
- 상관계수와 공분산을 구하는 함수
- corr, cov, corrwith


df.describe()
Out[357]:
| a | b | c | d | |
|---|---|---|---|---|
| count | 4.000000 | 4.000000 | 4.000000 | 4.000000 |
| mean | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| std | 5.163978 | 5.163978 | 5.163978 | 5.163978 |
| min | 0.000000 | 1.000000 | 2.000000 | 3.000000 |
| 25% | 3.000000 | 4.000000 | 5.000000 | 6.000000 |
| 50% | 6.000000 | 7.000000 | 8.000000 | 9.000000 |
| 75% | 9.000000 | 10.000000 | 11.000000 | 12.000000 |
| max | 12.000000 | 13.000000 | 14.000000 | 15.000000 |
In [359]:
df.a.unique()
Out[359]:
array([ 0, 4, 8, 12])
-
728x90