
728x90
0. Intro
- 대규모 Data를 별도의 label없이 입력의 일부를 예측대상으로 삼아서 학습하는 Self-supervised Learning
- 이를 통해 대규모 data로 사전 학습된 자연어 처리 용도로 사용될 수 있는 BERT
- GPT2,3에서 사용되는 masked language model 및 다음 단어를 예측하는 language modeling을 통해서 다양한 자연어 처리 task의 성능을 높여줌
- 실제 언어 생성 task로서 GPT2,3을 사용해서 실제 창작과정에 도움을 줄 수 있는 사례
1. Self-supervised Learning (자가 지도학습)
Unlabled data(given input, No desired output = No Label)
를 기반으로 하여 input의 일부를 예측/출력대상으로 삼아서 모델을 학습하는 방법
- 사람이 일일이 해 줘야 하는 labeling 과정이 없어도 있는 원시 data 만으로도 어떤 머신러닝 모델을 학습시킬 수 없을지에 대한 idea
- 원시 data 혹은 별도의 추가적인 label이 없는 입력 data만으로 해서 입력 data 중에 일부를 가려놓고 가려진 입력 data를 주었을 때 가려진 부분을 잘 복원 혹은 예측하도록 함
- 주어진 입력 data의 일부를 출력 혹은 예측의 대상으로 삼아서 모델을 학습하는 task
- Examples
- Inpainting Task
- 임의로 특정 부분을 가림 & 가려진 부분에 실제 pixel 값들을 잘 복원하도록 model을 학습
- 주어진 이미지에 있는 물체의 여러가지 특징들을 잘 파악해야만 task를 잘 수행할 수 있음
- Zigsaw Puzzle
- 주어진 이미지가 있을 때 해당 이미지를 특정 size의 patch로 자르고 그 순서를 임의로 바꿔준다
- Machine Learning으로 하여금 9개의 patch가 주어졌을 때 적절한 순서정보 혹은 패치의 정확한 위치를 학습
- Inpainting Task


자가지도 학습에 기반한 사전 학습 MODEL
- BERT
- GPT
대규모 data로 자가지도 학습을 통해 학습된 model은
내가 원하는 특정한 task를 풀기 위한 transfer learning의 형태로 학습 가능
- 자가지도 학습을 통해 내가 이 task를 위해 수집한 data를 가지고 특정 task를 하게 됨
- 다양한 layer에 걸쳐서 task를 학습하도록 만들어진 model은
- 최소한 앞쪽 layer에서는 물체를 잘 인식하기 위해 필요로 하는 패턴을 추출하도록 학습, 공통적으로 다른 여러 task에도 적용가능한/유용하게 사용될만한 정보들을 추출
- 뒤쪽으로 갈수록 주어진 task에 직접적으로 관련이 되는 (제 3의 task에는 적용이 불가능한) 정보들을 위주로 학습
- 앞쪽에 있는 Lower Layer들을 가져와서 주어진 model에 해당 task를 위한 output layer를 한 layer든 소수의 몇 개 layer들을 추가하여 model 학습을 진행
- 앞쪽에서 사전에 학습된 model로부터 배워둔 유용한 지식을 활용하여 해당 task를 위한 labeled data가 적을지라도 앞쪽에 있었던 사전학습된 Model를 가져와서 좋은 성능을 낼 수 있음

2. BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Transformer 모델을 기반으로 함
- 2가지 Task로 자가 지도 학습을 수행(Self-supervised Learning)
- MLM: Masked Language Modeling
- NSP: Next-sentence Prediction
- Bidirectional: MLM & NSP

BERT model 구조 및 입력/출력 Setting

- Transformer Model의 Encoder라고 생각
- Transformer Model의 Encoder기반의 BERT Model을 자가 지도 학습이라는 task의 형태로 학습시켜야 함
- 대규모의 text data를 학습 데이터로 사용
- 주어진 입력 문장을 BERT Model의 입력 sequence로 제공: 입력 데이터의 일부를 가려주고 그걸 예측하도록 함
- MLM
- 일부 단어들을 mask라는 special token으로 대체 & 원래는 해당 자리에 어떤 단어가 있었어야 했는지 맞추는 task로 학습
- NSP
- BERT Model을 fine-tuning에서 활용할 수 있도록 자가지도 학습하는 사전 학습 단계에서도 두 개의 문장이 연속되게 등장하여 의미관계가 밀접하게 주어져있는 그런 문장인지 아닌지를 판단하는 next sentence prediction을 수행하게 됨
- NSP를 수행하기 위해 두 개의 문장이 주어졌을 때 두 문장 사이& 문장 마지막에 SEP(separator token)을 추가하여 문장들 간의 구분과 끝을 model에게 알려줌
- CLS라는 Classification이라는 별도의 special token을 가장 첫 time step에 추가하여 BERT model에 input sequence로 줌
- Transformer Encoder의 관점에서 전체 sequence에 대한 각 단어들에 대해 필요한 정보들을 잘 encoding한 hidden state vector들을 단어별로 만들어줌
- CLS, MASK, NSP, 그 외의 단어들에 대해 encoding된 vector들이 각각 주어짐
- NSP
- 두 개의 문장이 실제로 한 document에서 연속적으로 등장했을 법한 문장일지 아닐지 binary classification을 하는 목적으로 CLS라는 token이 잘 encoding된 vector를 NSP가 output layer에 입력으로 주어 binary classification을 수행
- MLM
- MASK로 감춰진 혹은 대체된 단어가 encoding된 hidden state vector를 output layer에 입력으로 줘서 해당 자리에 들어가야 할 원래 단어를 맞추도록 하는 task로 학습이 진행됨

MLM: Masked Language Model
- 주어진 input sequence에 대해 Random하게 특정 비율만큼 혹은 특정 정해진 확률로 각각의 단어를 MASK token으로 바꿀지 or 그대로 둘지에 관한 전처리를 수행하게 됨
- BERT Model에서는 전체 단어가 100개 정도 있다면 15%의 비율로 mask라는 단어로 대체해서 해당 단어를 맞출 수 있도록 하는 task를 구상함
- Problem
- 15%의 비율에 해당하는 단어를 맞추도록 할 때 이 단어를 무조건 mask라는 단어로 대체하면 대체되지 않은 다른 token들을 encoding할 때는 encoding을 게을리 할 수 있음
- Solution
- 15개의 단어들 중 약 80%만을 실제 mask token으로 바꿔서 입력 sequence에 반영
- 나머지 약 10%의 단어를 random하게 다른 단어로 대체 -> 최종적으로 encoding한 hidden state vector를 가지고 해당 자리에 들어갈 단어가 무엇인지 예측하도록 했을 때 masked 단어들 뿐만 아니라 다른 단어들도 최대한 유용한 정보를 encoding 하도록 model이 학습될 것
- 마지막 10%의 단어는 해당 단어를 그대로 유지시키기 & 해당 단어가 무슨 단어여야 할지를 맞추도록 하는 방식으로 학습 진행
- 해당 자리에 원래 들어갈 단어가 무엇인지를 물어봤을 때 물어봤다는 사실만으로 '적어도 지금주어진 단어는 답이 아니겠구나'라는 잘못된 패턴을 Deep Learning Model이 배우지 않도록 방지
- 원래 단어가 맞다고 예측할 수 있도록 하는 model을 설계

- 전체 input 중 MASK 처리하는 단어의 비율 = $k$
- $k$가 너무 클 경우
- 너무 많은 단어를 가리게 되어 주어진 문장 상에 온전히 남아있는 단어가 몇 개 되지 않음
- 실제 masking된 단어들을 잘 예측하기 위해 필요로 하는 정보가 절대적으로 부족
- $k$가 너무 작을 경우
- 긴 문장이 주어졌을 때 예측 task로 사용할 단어수가 너무 적게되면 많은 계산 과정을 통해 encoding했음에도 실제 문제로 출제되는 것이 몇 문제 되지 않음 -> 학습 과정이 전체적으로 비효율이 될 수 있으므로 비율이 더 작지 않도록 설정
- $k$가 너무 클 경우
NSP: Next-sentence Prediction
- 2개의 문장을 연속으로 주게됨
- 각각의 문장은 SEP token으로 구별하여 각각의 문장이 DL로 하여금 구분할 수 있도록 추가적인 정보를 제공
- 앞에는 CLS token을 추가해서 전체 sequence를 encoding하고 나서 output layer에 통과해서 주어진 문장 두 개가 실제 original 문서에서 연속되게 등장한 두 개의 문장이면 'next sentence 관계에 있다' 라고 예측
- 두 개의 무관한 document로부터 두 문장을 random하게 뽑아서 sequence를 구성한다면 두 문장 사이의 관련성이 많이 떨어지므로 문맥이나 관계를 잘 보고 CLS token으로부터 encoding된 hidden state vector의 next sentence prediction task의 binary classification 결과가 'next sentence가 아니다'라고 예측하도록 학습이 진행됨
- CLS Token
- 두 문장이 실제 next sentence인지, 아닌지를 판별하는데 필요로 하는 정보들을 주어진 입력 sequence 내에 여러 단어들로부터 self-attention module을 통해 정보들을 잘 추출해오도록 학습이 진행
- CLS token으로부터 encoding된 hidden state vector가 전체 sequence의 내용들을 잘 종합하여 반영함
- target task에 새로운 fully-connected layer를 달고 거기에 hidden state vector를 통과시켜 softmax classification을 수행

- L: Layer 개수, self-attention block이 stacking된 layer
- H: Hidden state vector의 dimension (클수록 더 많은 정보를 encoding가능)
- A: Hyperparameter, Self-attention block에서 multi-head attention을 사용할 때 head의 개수 ($W^{q}, W^{k}, W^{v}$인 linear transformation set 개수)
- Transformer Model에서는 사전에 미리 정의된 sin, cos 함수들을 사용해서 position encoding했으나 여기서는 position encoding에 사용되는 함수 자체도 두 개의 pre-training task를 통해 최적화하는 과정을 거친다
- 두 가지 task(MLM, NSP)를 위해 별도의 추가적인 token 이였던 CLS, SEP을 같이 추가하여 pre-training 진행

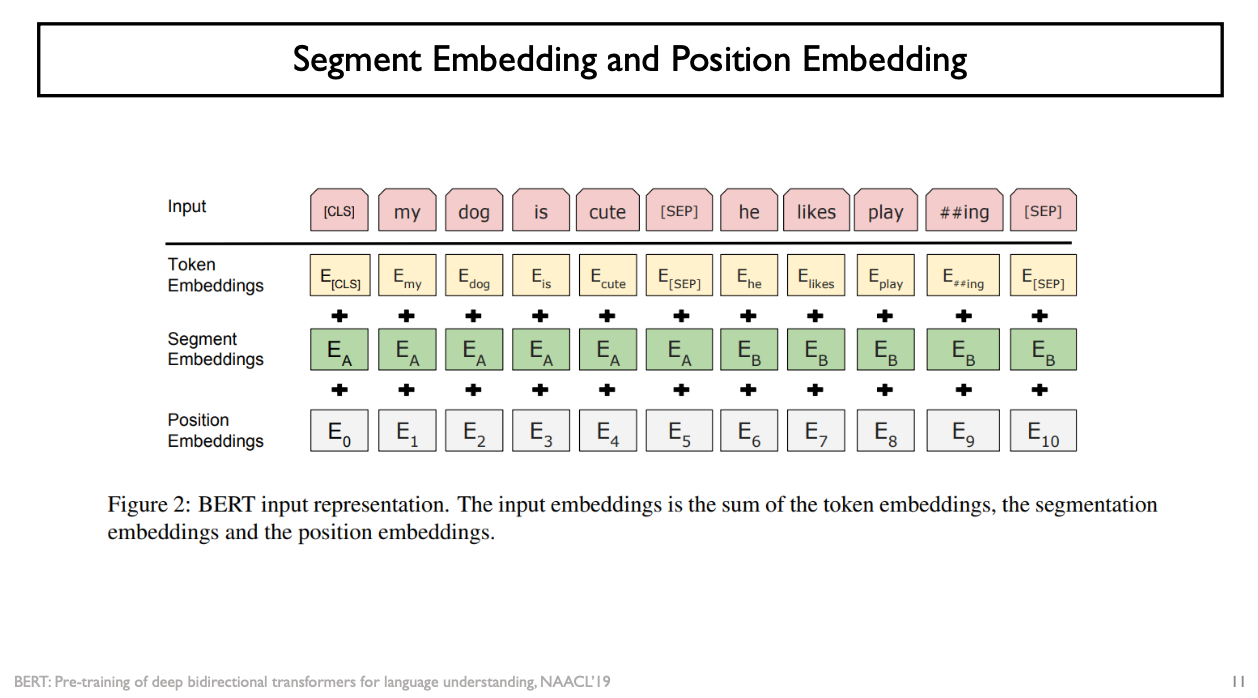
Segment Embedding and Position Embedding
- 추가적인 position encoding의 보완되는 정보로서 segment embedding이라는 것을 시행함
- 기존에 주어지는 각각의 워드들의 입력 vector에 해당 word가 몇 번째 position에 나타났는가 라는 position 정보를 position vector로 더하고
- 어떤 특정한 단어가 항상 2개의 문장 중에 한 문장에 속해서 단어가 입력으로 주어질 것인데, 첫 번째 문장에서 주어진 단어인지, 두 번째 문장에서 주어진 단어인지 구분할 수 있도록 구별되는 segment vector를 입력으로 줘서 입력 vector에 추가
Various Fine-Tuning Approaches
- 다양한 특정 task로 fine-tuning할 때는 fine-tuning할 task의 어떤 problem setting에 따라서 BERT를 다양하게 활용가능
- (d) word-level classification task: 주어진 문장의 각 단어의 품사가 무엇인지
- 입력 문장의 각 단어들을 BERT Model의 입력으로 줌
- output으로 나온 hidden state vector & output layer 하나를 linear layer로서 같이 달아서 softmax에 기반한 classification을 수행하되 그 카테고리들은 품사를 예측하도록 하는 fine-tuning의 형태
- (b) sentence-level classification task
- 사전학습 당시에 CLS token이 주어진 전체 sequence의 의미나 문맥을 잘 종합한 용도로서 NSP을 수행하도록 학습이 진행됨
- CLS에 최종적인 encoding된 token을 입력으로 줘서 추가적인 fully-connected layer하나를 달아서 긍정인지/부정인지를 예측하는 fine-tuning task
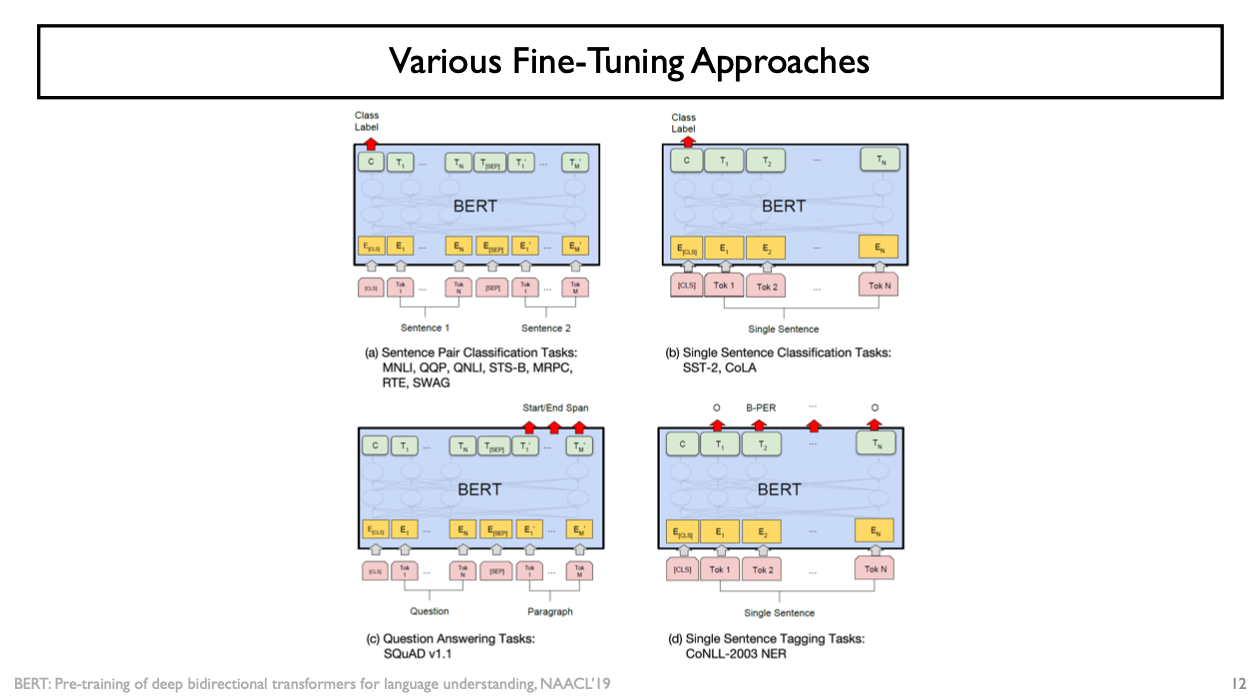
- (a) 다수의 문장을 보고 거기서부터 예측을 수행해야 하는 target task 또한 존재
- Ex) Natural Language Inference Task
- 2개의 문장이 하나의 data item으로 주어짐
- 해당 2개의 문장이 논리적인 내포 관계, 상호 모순 관계, 논리적으로 무관한 관계인지를 예측하도록 하는 task
- (c) 기계독해 task
- 일단 질문이 주어지고, 해당 질문에 답을 포함하고 있는 어떤 지문에 해당하는 data가 또 주어짐 (Question / Paragraph)
- 질문에 대한 답을 주어진 지문에서 특정한 문구를 발췌해서 예측하도록 하는 task로도 BERT Model을 fine-tuning할 수 있음
- 주어진 지문의 각각의 단어들을 encoding한 vector들을 대상으로 해서 모두 다 동일한 fully-connected layer에 통과를 시켜 하나의 scalar값을 얻고 이를 logit 값으로 활용하여 softmax에 입력으로 주고 classification을 수행
- 발췌할 문구의 가장 첫번째 단어를 prediction을 해주고 또 다른 fully -connected layer를 더 달아서 나온 scalar 값을 가지고 softmax를 취하면 발췌할 문구의 가장 마지막 단어를 예측하도록 하는 task를 수행
BERT 성능비교
- 다양한 종류의 자연어 학습 task에서 사전 학습된 BERT Model을 fine tuning 시켰더니 기존의 다른 model 보다 유의미하게 좋은 성능을 일관되게 보임

3. GPT Series
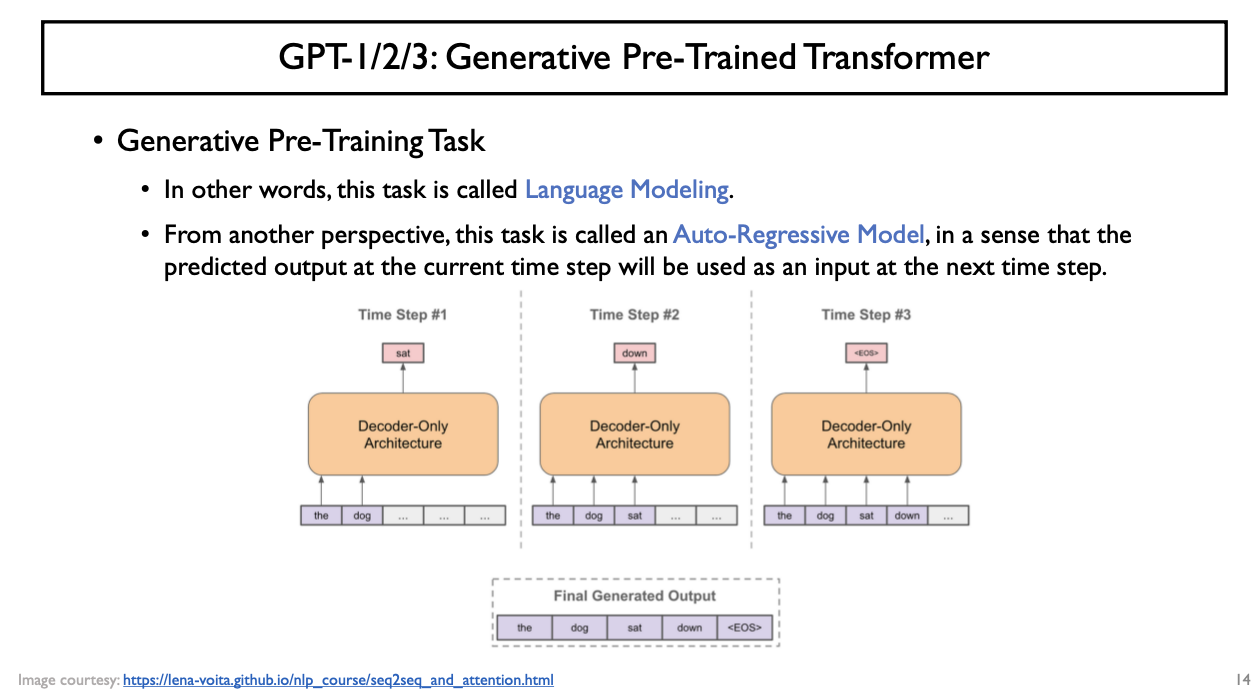
GPT: Generative Pre-Trained Transformer
- Transformer Model의 Decoder를 사용
- Decoder
- Masked Self-attention이 가능
- Auto-regressive한 setting에서 주어진 입력 sequence에 대해 현재 time step기준 다음 time step에 나타날 단어를 예측하는 task를 수행하는 model
- 단어 단위의 level에서 주어진 대규모의 text data로부터 문장들을 가져옴
- Word level의 language modeling task를 학습하는 것이 GPT Model의 핵심 idea
GPT2
- Transformer에서 제안된 self-attention block를 굉장히 깊게 쌓아서 model size를 키움
- Model을 학습하기 위해 굉장히 많은 양의 text data를 사용
- 사전 학습을 진행할 당시에 '최대한 양질의 data를 사용했을 때 다음 단어를 예측하는 task가 더 유의미한 성능을 낼 것이다' 라고 생각하고 흥미로운 트릭을 사용: 학습 Data를 최대한 양질의 data로 만들어지도록 구성
- 질문을 올리면 해당 글에 대해 여러 사람들이 답글을 다는데, 여러 답글 중 3개 이상의 '좋아요'를 받았으며 답글 중 링크가 포함되어있을 때 해당 링크에 있는 문서를 실제 학습 data로 수집해서 이 data로 language modeling task를 학습

- 글의 뒷부분을 창작하는 용도로도 활용

- Zero-shot setting에서의 down-stream task에 바로 적용 가능함
- Summarization Task
- TL;DR = too long; didn't read
- TL;DR 이후에 긴 글에 대한 한 문장의 요약문을 제시하는 경우가 많음
- TL;DR 이라는 단어가 input sequence에 주어졌다면 '앞에 있는 지문을 요약해야겠구나'라는 상황을 인식해서 주어진 지문에 대한 요약을 생성
- Zero-shot
- summarization이라는 target task를 학습하기 위해서는 사전 학습된 model을 가져와서 입력 지문 + 그에 해당하는 summarization된 정답 문장 + 해당 문장과 pair를 이루고 있는 labeled된 학습 Data를 가지고 주어진 model을 fine-tuning하는 과정을 거치게 됨
- 다만 GPT2의 경우 task를 위해 직접적으로 수집된 학습 data를 전혀 쓰지 않았음에도 다음 단어를 수행하는 GPT2 model이 summarization task를 수행할 수 있는 능력을 보여주었다는 측면에서 zero-shot이라는 말이 붙게 됨

GPT3
- GPT2와 학습된 task와 model의 구조 자체는 거의 동일
- Transformer Model에 self-attention block을 사용한 decoder를 그대로 계승
- 학습 data가 굉장히 커짐
- model의 self-attention block의 layer를 더더욱 많이 쌓음
- BERT와 GPT2 모델이 가졌던 parameter 수 대비 훨씬 더 많은 layer 수를 가지고 거기에 학습에 필요로 하는 약 1,750억 개에 달하는 parameter를 가지는 transformer decoder model을 학습한 것

- Few-Shot Learning
- 앞에 원하는 입력 text를 decoder에 기본 입력으로 제공
- Zero-Shot Learning: 현실적으로 학습 data를 전혀 사용하지 않은 상태에서의 해당 task의 성능은 상당히 제한적
- GPT3는 소수의 예시 data 혹은 학습 data를 글의 일부 or 지문의 일부의 형태로서 제공 -> language modeling task 자체를 바로 task에 활용
- One-shot learning task: 학습 data 한 개를 주어서 task를 수행하도록 함
- Few-shot learning task: 예시 data를 세 개 혹은 네 개 이렇게 몇 개를 줬을 때 성능이 zero/one-shot learning task보다는 높음
- Prompt Tuning
- 지문을 어떤 형태로 구성했을 때 GPT3이라는 고정된 model이 내가 원하는 task의 성능을 최대한 높이는 형태로 동작할 것인가
- 앞쪽에 있는 내용을 어떻게 구성할 것인가 -> 가장 최적의 형태를 찾는중
- 앞에 있는 지문 자체가 GPT의 입력 sequence로 주어지는 하나의 prompt라고 본다면 해당 내용을 어떻게 잘 구성했을 때 GPT3가 내가 원하는 task를 가장 잘 수행할 수 있는가

- Copliot
- Github, Microsoft에서 만듦
- 프로그램을 자동 완성해주는 서비스
- 프로그램 data만으로 주어진 사전 학습된 GPT3 model을 가져와 fine-tuning한 model을 통해 프로그램의 자동 완성 task를 잘 구현할 수 있는 model로 특화함


728x90