
1. Problem
Pytorch Framework를 이용하여 CartoonGAN 학습을 위해 Image들을 불러와 학습하는데, 속도가 상당히 느리다.
구글 코랩을 사용하여 Google Drive의 Dataset 폴더에 이미지들을 업로드 해놓고 불러오도록 설정한다.
GPU를 사용해도 한 epoch을 도는데 시간이 너무 많이 걸리는 문제가 발생한다.
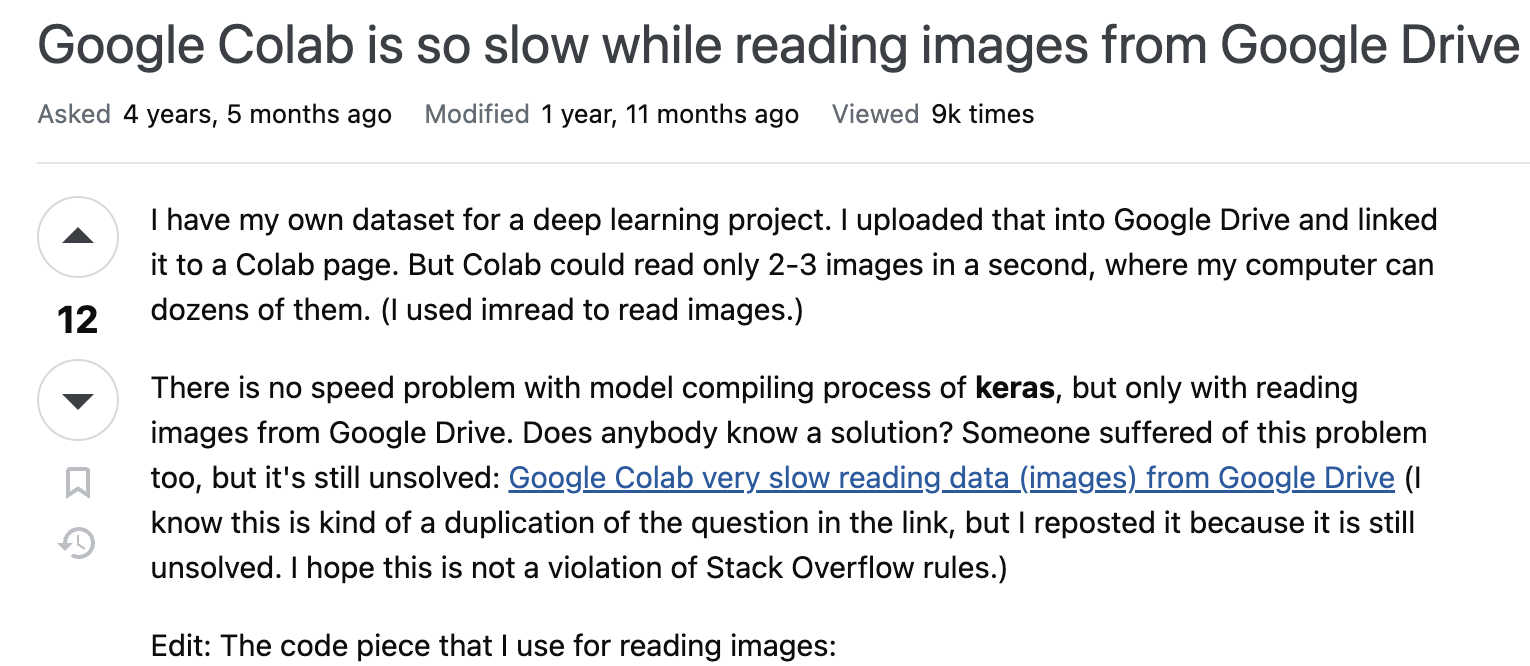
이와 같은 현상에 대해 Stackoverflow에서 미리 언급했음을 찾아볼 수 있다.
Google Colab is so slow while reading images from Google Drive
I have my own dataset for a deep learning project. I uploaded that into Google Drive and linked it to a Colab page. But Colab could read only 2-3 images in a second, where my computer can dozens of...
stackoverflow.com
2. Cause
이는 이미지들을 Google Drive에서 Colab 환경으로 불러오는 속도가 느려서 일어나는 문제라고 볼 수 있다.
이를 해결하기 위해서는:
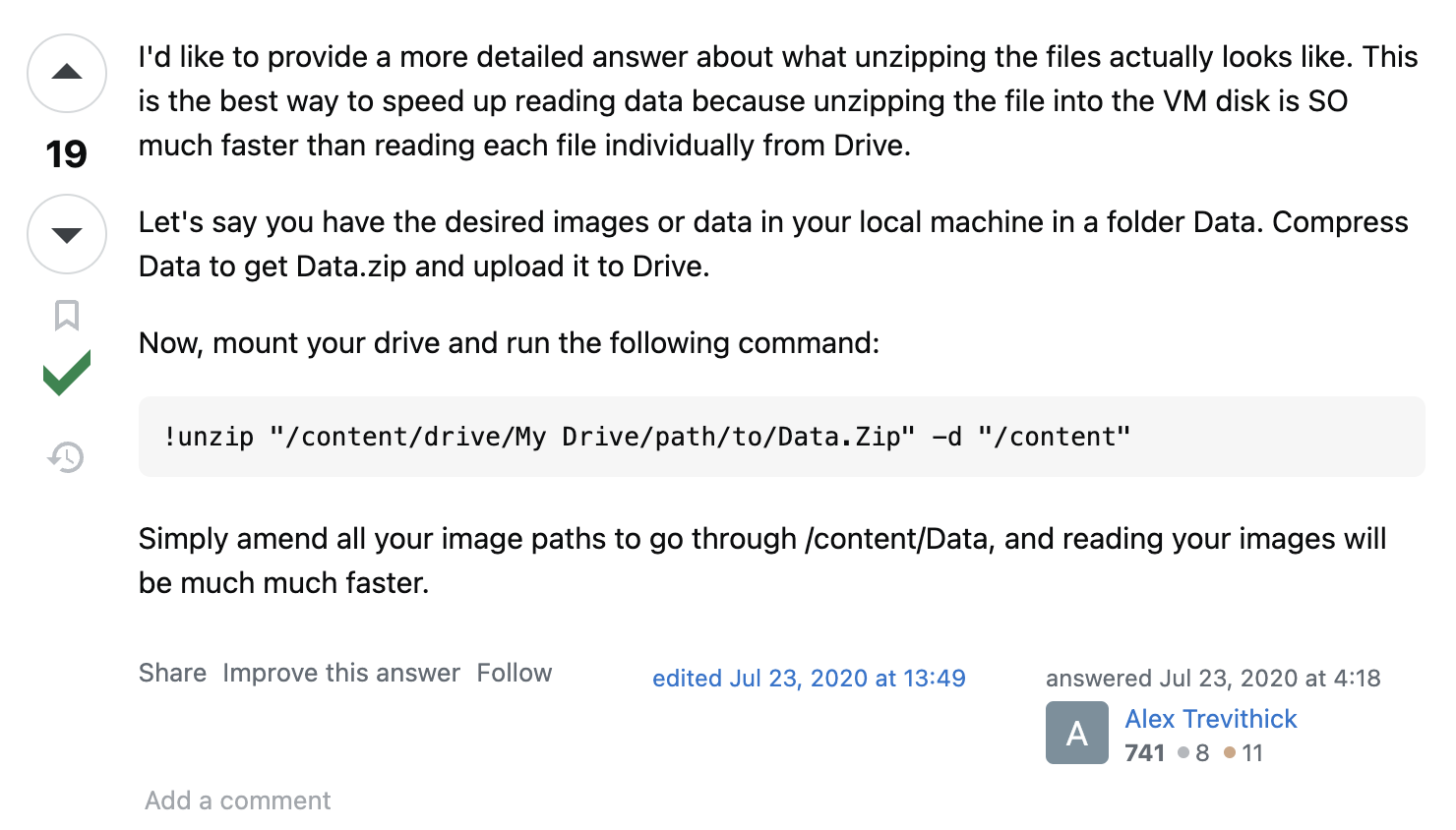
1) ZIP 압축파일을 Google Drive에 올린다.
Dataset의 image들을 바로 Colab VM에 올리기에는 용량이 커서
일단 ZIP 압축파일을 Google Drive에 올린다.
2) Google Drive의 ZIP 압축파일을 Colab 가상환경 (VM)에서 압축을 푼다.
Colab 가상환경은 경로가 아래와 같이 기술되어 있으면 된다.
destination_path = '/content/image'
위와 같이 'MyDrive'라는 Google Drive에서 Image Data를 불러오지만 않으면 된다.
3. Code Implementation
이를 실제로 사용한 코드는 아래와 같다.
주의할 점이 몇가지 있는데:
1) datasets dictionary에는 실제 key인 ZIP 압축파일이 위치한 경로가 value로 들어가야 한다.
2) ZIP 압축파일을 풀었을 때 나오는 Folder Name이 datasets dictionary의 각 key 값과 동일해야 한다.
3) Destination Path인 dst_path는 Google Drive의 경로가 아닌 Colab VM의 경로로 설정해야 한다.
'/content/dataset' or '/content/images' 등과 같이 /content 뒤에 본인이 원하는 경로를 작성해주면 된다.
Google Drive의 경로가 아니여야 하므로 '/content/drive/MyDrive/dataset.zip'과 같이
'drive/MyDrive'라는 단어가 경로가 들어가면 안 된다.
import zipfile
import os
import shutil
def unzip_and_count(dataset, dst_path):
dst_file = os.path.join(dst_path, os.path.basename(dataset))
if not os.path.exists(dst_path):
os.makedirs(dst_path)
shutil.copy(dataset, dst_file)
with zipfile.ZipFile(dst_file, 'r') as file:
file.extractall(dst_path)
train_dir = os.path.join(dst_path, os.path.splitext(os.path.basename(dataset))[0])
print(f'total images in {os.path.basename(dataset)}:', len(os.listdir(train_dir)))
# zip files들 경로 지정
datasets = {
'real_image.zip': '/content/drive/MyDrive/AI/BITAmin/Project/2024_spring/CartoonGAN/datasets/real_image.zip',
'real_cartoon.zip': '/content/drive/MyDrive/AI/BITAmin/Project/2024_spring/CartoonGAN/datasets/real_cartoon.zip',
'smoothed_cartoon.zip': '/content/drive/MyDrive/AI/BITAmin/Project/2024_spring/CartoonGAN/datasets/smoothed_cartoon.zip'
}
# Destination directory
dst_path = '/content/images'
# Unzip and count images for each dataset
for name, path in datasets.items():
unzip_and_count(path, dst_path)
1. Problem
Pytorch Framework를 이용하여 CartoonGAN 학습을 위해 Image들을 불러와 학습하는데, 속도가 상당히 느리다.
구글 코랩을 사용하여 Google Drive의 Dataset 폴더에 이미지들을 업로드 해놓고 불러오도록 설정한다.
GPU를 사용해도 한 epoch을 도는데 시간이 너무 많이 걸리는 문제가 발생한다.
이와 같은 현상에 대해 Stackoverflow에서 미리 언급했음을 찾아볼 수 있다.
Google Colab is so slow while reading images from Google Drive
I have my own dataset for a deep learning project. I uploaded that into Google Drive and linked it to a Colab page. But Colab could read only 2-3 images in a second, where my computer can dozens of...
stackoverflow.com
2. Cause
이는 이미지들을 Google Drive에서 Colab 환경으로 불러오는 속도가 느려서 일어나는 문제라고 볼 수 있다.
이를 해결하기 위해서는:
1) ZIP 압축파일을 Google Drive에 올린다.
Dataset의 image들을 바로 Colab VM에 올리기에는 용량이 커서
일단 ZIP 압축파일을 Google Drive에 올린다.
2) Google Drive의 ZIP 압축파일을 Colab 가상환경 (VM)에서 압축을 푼다.
Colab 가상환경은 경로가 아래와 같이 기술되어 있으면 된다.
destination_path = '/content/image'
위와 같이 'MyDrive'라는 Google Drive에서 Image Data를 불러오지만 않으면 된다.
3. Code Implementation
이를 실제로 사용한 코드는 아래와 같다.
주의할 점이 몇가지 있는데:
1) datasets dictionary에는 실제 key인 ZIP 압축파일이 위치한 경로가 value로 들어가야 한다.
2) ZIP 압축파일을 풀었을 때 나오는 Folder Name이 datasets dictionary의 각 key 값과 동일해야 한다.
3) Destination Path인 dst_path는 Google Drive의 경로가 아닌 Colab VM의 경로로 설정해야 한다.
'/content/dataset' or '/content/images' 등과 같이 /content 뒤에 본인이 원하는 경로를 작성해주면 된다.
Google Drive의 경로가 아니여야 하므로 '/content/drive/MyDrive/dataset.zip'과 같이
'drive/MyDrive'라는 단어가 경로가 들어가면 안 된다.
import zipfile
import os
import shutil
def unzip_and_count(dataset, dst_path):
dst_file = os.path.join(dst_path, os.path.basename(dataset))
if not os.path.exists(dst_path):
os.makedirs(dst_path)
shutil.copy(dataset, dst_file)
with zipfile.ZipFile(dst_file, 'r') as file:
file.extractall(dst_path)
train_dir = os.path.join(dst_path, os.path.splitext(os.path.basename(dataset))[0])
print(f'total images in {os.path.basename(dataset)}:', len(os.listdir(train_dir)))
# zip files들 경로 지정
datasets = {
'real_image.zip': '/content/drive/MyDrive/AI/BITAmin/Project/2024_spring/CartoonGAN/datasets/real_image.zip',
'real_cartoon.zip': '/content/drive/MyDrive/AI/BITAmin/Project/2024_spring/CartoonGAN/datasets/real_cartoon.zip',
'smoothed_cartoon.zip': '/content/drive/MyDrive/AI/BITAmin/Project/2024_spring/CartoonGAN/datasets/smoothed_cartoon.zip'
}
# Destination directory
dst_path = '/content/images'
# Unzip and count images for each dataset
for name, path in datasets.items():
unzip_and_count(path, dst_path)