
728x90
import torch
import torch.nn as nn
import torch.nn.functional as F
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
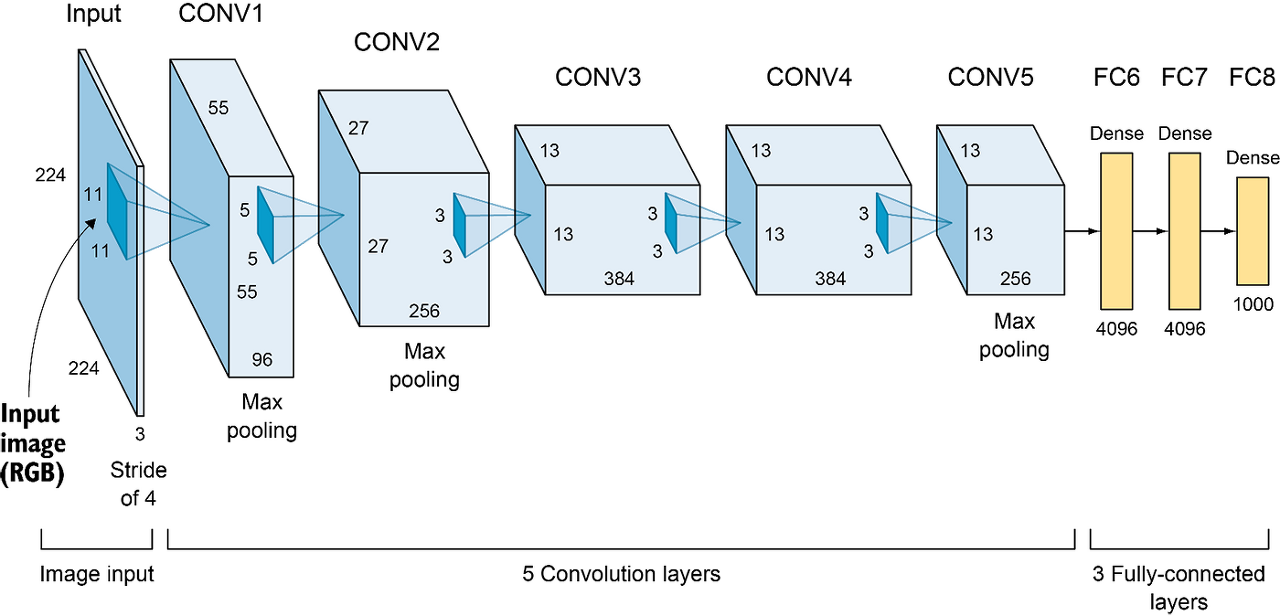
### CNN Layers
self.features = nn.Sequential(
# Conv1
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4),
nn.ReLU(inplace=True), # non-saturating function
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 27 * 27 * 96
# Conv2
nn.Conv2d(
in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2
),
nn.ReLU(inplace=True), # non-saturating function
nn.LocalResponseNorm(size=5, alpha=1e-4, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # 13 * 13 * 256
# Conv3
nn.Conv2d(
in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1
),
nn.ReLU(inplace=True), # non-saturating function, 13 * 13 * 384
# Conv4
nn.Conv2d(
in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1
),
nn.ReLU(inplace=True), # non-saturating function, 13 * 13 * 384
# Conv5
nn.Conv2d(
in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1
),
nn.ReLU(inplace=True), # non-saturating function
nn.MaxPool2d(kernel_size=3, stride=2), # 6 * 6 * 256
)
### FC Layers
self.classifier = nn.Sequential(
# FC1
nn.Dropout(p=0.5, inplace=True),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
# FC2
nn.Dropout(p=0.5, inplace=True),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
# Dense
nn.Linear(4096, num_classes),
)
self.init_bias_weights()
# bias, weight 초기화
def init_bias_weights(self):
for layer in self.features:
if isinstance(layer, nn.Conv2d):
nn.init.normal_(layer.weight, mean=0, std=0.01)
nn.init.constant_(layer.bias, 0)
# Conv 2, 4, 5번째 Layer는 bias를 1로 초기화
nn.init.constant_(self.features[4].bias, 1)
nn.init.constant_(self.features[10].bias, 1)
nn.init.constant_(self.features[12].bias, 1)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
Q. Batch Normalization은 Conv Layer와 Activation Function 사이에 위치하는데, LRN은 Conv Layer와 Activation Function 뒤에 위치하는 이유가 뭐야?
A. 일반적으로 BatchNorm은 conv layer와 activation 사이에 위치하지만, AlexNet에서 사용된 Local Response Normalization (LRN)은 activation 뒤에 위치한다.
이 구조는 LRN이 활성화 함수의 출력에 대한 정규화를 수행하기 때문이다.
LRN의 목적은 인접한 피처 맵 간의 경쟁을 강화하여, 각 뉴런의 응답을 정규화하여 보다 강력한 피처가 더욱 두드러지게 만드는 것이다.
이 접근법은 네트워크가 보다 복잡한 함수를 학습하는 데 도움을 주고, 과적합을 방지하는 효과가 있다.따라서 AlexNet에서는 activation 후에 LRN을 적용하는 것이다.
728x90