
python List vs numpy array
NumPy는 Python List에 비해 빠른 연산을 지원하고 메모리를 효율적으로 사용한다
| NumPy array | 정적 할당 | 불가능 | 단일 타입 | 빠름 |
| Python List | 동적 할당 | 가능 | 혼합 타입 | 느림 |
List
- 가변적인 크기
- 객체의 참조를 저장하는 배열로 구성
- 리스트의 각 원소는 서로 다른 데이터 타입을 가질 수 있음
- 메모리는 공간이 필요하거나 확보되면 동적으로 재할당-> 메모리 사용량이 높아지고 메모리 접근이 느려질 수 있음
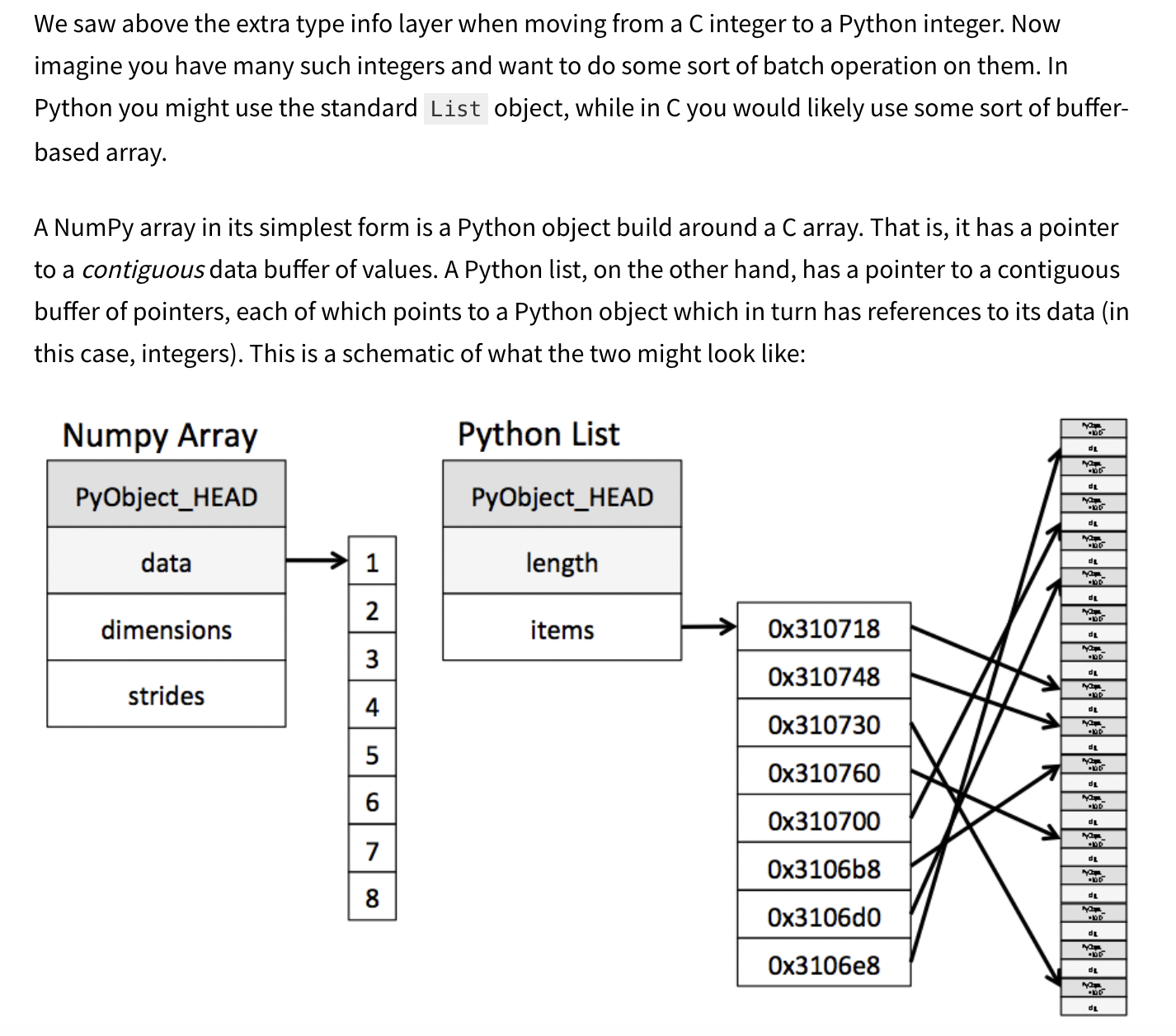
Numpy.ndarray
- List와 가장 큰 차이점, Dynamic typing not supported
- 실행시점에 data type을 결정 X : 미리 결정하고 시작
- 메모리 공간을 어떻게 잡을지 미리 선언
- 고정된 크기 -> 메모리 Size 모두 동일
- 동일한 데이터 타입의 원소를 갖는 연속적인 메모리 블록에 저장-> 메모리 사용량이 최소화
- Memory Address에 접근하기 쉬움 (연속적으로 저장되어있으므로)
- 배열의 크기를 변경하려면 새로운 메모리 블록에 배열을 복사
뷰(view)
- ndarray를 슬라이싱, 인덱싱 등을 할 때 원본 데이터를 복사하지 않고, 뷰를 통해 참조됨
- 파이썬 리스트는 리스트의 조각들을 변경해도 원본 리스트에 변화가 없음
pylist = [1,2,3,4,5]
part_pylist = pylist[2:] #3,4,5
part_pylist[0] = 0
print(pylist)
print(part_pylist)[1, 2, 3, 4, 5]
[0, 4, 5]
- 그런데 Numpy.ndarray는 배열 조각을 변경하면 원본 배열에도 변화가 생긴다. 이 배열 조각을 원본 배열의 뷰(view) 라고 부름
nparray = np.array([1,2,3,4,5])
part_nparray = nparray[2:]
part_nparray[0] = 0
print(nparray)
print(part_nparray)[1 2 0 4 5]
[0 4 5]
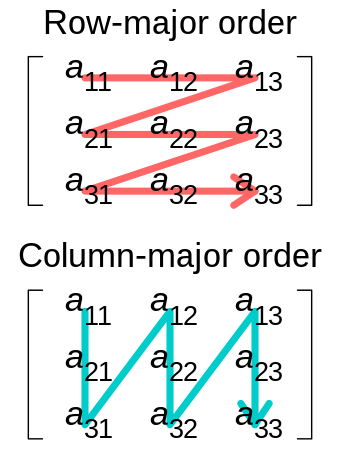
order
- 다차원 배열의 메모리 배치 방식
- row-major order(C언어 스타일), column-major order(포트란 언어 스타일)
numpy의 order 매개변수
크게 두가지
- C: 행 우선 배치 -> 행이 먼저 채워지고 다음 행으로 이동(기본값)
- F: 열 우선 배치 -> 열이 먼저 채워지고 다음 열로 이동
REFERENCE
Python Numpy 강좌 : 제 13강 - 메모리 레이아웃
메모리 레이아웃(Memory Layout)
076923.github.io
https://numpy.org/devdocs/dev/internals.html
Internal organization of NumPy arrays — NumPy v2.0.dev0 Manual
Internal organization of NumPy arrays It helps to understand a bit about how NumPy arrays are handled under the covers to help understand NumPy better. This section will not go into great detail. Those wishing to understand the full details are requested t
numpy.org
https://jakevdp.github.io/blog/2014/05/09/why-python-is-slow/
Why Python is Slow: Looking Under the Hood | Pythonic Perambulations
So Why Use Python?¶ Given this inherent inefficiency, why would we even think about using Python? Well, it comes down to this: Dynamic typing makes Python easier to use than C. It's extremely flexible and forgiving, this flexibility leads to efficient use
jakevdp.github.io
https://en.wikipedia.org/wiki/Row-_and_column-major_order